

 Artificial Intelligence is changing the world around us, from self-driving cars to Google maps predicting traffic. If you’re preparing for a job interview in the AI field, understanding AI concepts is super important.
Artificial Intelligence is changing the world around us, from self-driving cars to Google maps predicting traffic. If you’re preparing for a job interview in the AI field, understanding AI concepts is super important.
This page is designed to help you get ready by providing common AI-related questions you might face, along with brief, easy-to-understand answers. Whether you’re new to AI or brushing up on your skills, these questions cover wide range of topics like machine learning, neural networks, and AI ethics for a deeper understanding of concepts.
Our experts have made sure the answers are well-written so you can feel confident learning and rehearsing from them. Use this interview guide to practice, learn important concepts, and understand how to give answers. Let’s get one step closer to acing your AI interview!
Answer:
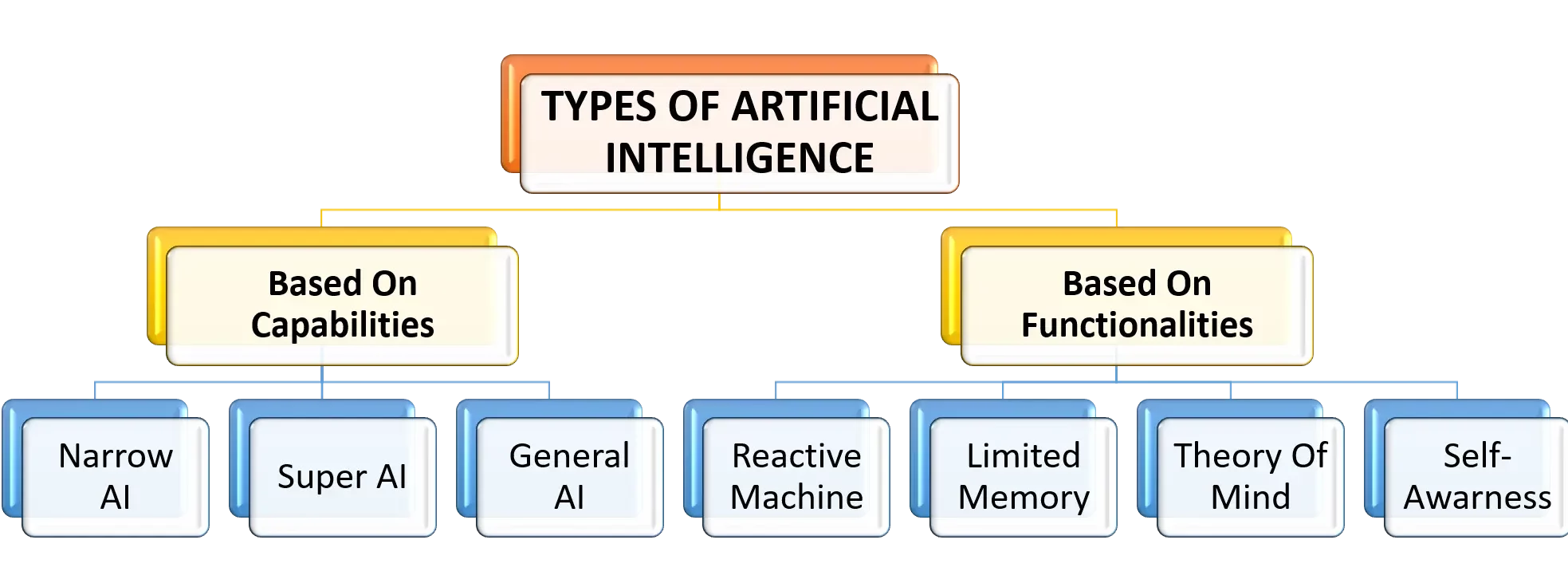
There are seven types of Artificial Intelligence. Which are as follows:
- Weak AI or Narrow AI: These are designed to perform dedicated tasks. They cannot perform beyond their capabilities. Apple’s Siri and IBM’s Watson are some examples of weak AI or narrow AI.
- General AI: General AI can perform any intellectual task like humans. Currently, there is no system in the world that can be categorized under general AI. Researchers, however, are focused on developing AI devices that can perform tasks as perfectly as humans.
- Super AI: Super AI is the level of Artificial Intelligence at which it can pass the intelligence of humans and can perform tasks better than humans. Super AI is still a hypothetical concept.
- Reactive Machines: These kinds of machines react in the best possible way in a current situation. They do not store memories or experiences. IBM’s Deep Blue system and Google’s Alpha go are some examples of reactive machines.
- Limited memory: These machines store experiences, but only for a limited amount of time. For example, smart cars store the information of nearby cars, their speed, speed limit, route information for a limited amount of time.
- Theory of mind: The theory of machine AI is a theoretical concept. They might be able to understand human emotions, beliefs, society, and might be able to interact like humans.
- Self-awareness: Self-awareness AI is the future of AI. It is expected that these machines will be super-intelligent, having their own consciousness, emotions, and self-awareness.
Answer:
- Strong AI is a theoretical form of AI with a view that machines can develop consciousness and cognitive abilities equal to humans. Weak AI, also called narrow AI, is AI with limited functionality. It refers to building machines with complex algorithms to accomplish complex problem-solving, but it does not show the entire range of human cognitive capabilities.
- Strong AI can perform a wide range of functions. In comparison to strong AI, weak AI has fewer functions. Weak AI is unable of achieving self-awareness or demonstrating the full spectrum of human cognitive capacities and operate within a pre-defined range of functions.
- Strong AI-powered machines have a mind of their own, and they can think and accomplish tasks on their own. While, Weak AI-powered machines do not have a mind of their own.
- No machine of strong AI exists in reality. Examples include Siri or Google Assistant.
Answer:
A Bayesian network is a probabilistic graphical model based on a set of variables and their dependencies, represented in the form of an acyclic graph. Bayesian networks are based on probability distribution, and they predict outcomes and detect anomalies using probability theory. The Bayesian networks are used to perform tasks such as prediction, detecting anomalies, reasoning, gaining insights, diagnostics, and decision-making. A Bayesian network, for example, could be used to illustrate the probability correlations between diseases and symptoms. The network may be used to calculate the chances of certain diseases being present based on symptoms.
Answer:
Following are the agents available in Artificial Intelligence:
- Simple Reflex Agents: Simple reflex agents ignore the history of the environment and its interaction with the environment and act entirely on the current situation.
- Model-Based Reflex Agents: These models perceive the world according to the predefined models. This model also keeps track of internal conditions, which can be adjusted according to the changes made in the environment.
- Goal-Based Agents: These kinds of agents react according to the goals given to them. Their ultimate aim is to reach that goal. If the agent is provided with multiple-choice, it will select the choice that will make it closer to the goal.
- Utility-based Agents: Sometimes, reaching the desired goal is not enough. You have to make the safest, easiest, and cheapest trip to the goal. Utility-based agents chose actions based on utilities (preferences set) of the choices.
- Learning Agents: These kinds of agents can learn from their experiences.
Answer:
Overfitting is a concept in data science when a data point does not fit against its training model. When the raining model is fed with data, there is a possibility that it might encounter some noise that cannot fit into the statistical model. This happens when the algorithm cannot perform accurately against unseen data.
Answer:
Fuzzy logic (FL) is a method of reasoning in Artificial Intelligence that resembles human reasoning. According to this logic, the outcome can take any values between TRUE and FALSE (digitally, 0, or 1). For example, the outcome can be certainly yes, possibly yes, not sure, possibly no, or certainly no.
Answer:
A chatbot is a computer program that simulates and processes human conversations. They can interact with us just like any other real person. Chatbots can be a basic program that answers a query in a single line or can be sophisticated assistants that can learn and evolve to attain an increasing level of personalization as they gather and process information.
Chatbots have now developed to a level where they can chat with a person without giving the impression that they are talking to a robot. They can work continuously 24*7 even when the customer support executives of organizations are not around. Furthermore, they can harness the power of data and can properly address the grievances of the customer. Therefore, chatbots can be deployed to deliver the best customer support and can decrease the cost of customer service of an organization considerably.
Answer:
Humans are visual, and AI is designed to emulate human brains. Therefore, teaching machines to recognize and categorize images is a crucial part of AI. Image recognition also helps machines to learn (as in machine learning) because the more images that are processed, the better the software gets at recognizing and processing those images.
Answer:
AI’s inference engine extracts valuable learning from its knowledge base by following a set of predefined logical rules. For the most part, it operates in two distinct modes:
- Backward Chaining: It starts with the end aim and then works backward to figure out the evidence that points in that direction.
- Forward Chaining: It begins with facts that are already known and then claims new facts.
Answer:
A rational agent is a system that makes decisions based on maximizing a specific objective. The concept of rationality refers to the idea that the agent’s decisions and actions are consistent with its objectives and beliefs. In other words, a rational agent is one that makes the best decisions possible based on the information it has available. This is often formalized through the use of decision theory and game theory.
Answer:
Reward maximization term is used in reinforcement learning, and which is a goal of the reinforcement learning agent. In RL, a reward is a positive feedback by taking action for a transition from one state to another. If the agent performs a good action by applying optimal policies, he gets a reward, and if he performs a bad action, one reward is subtracted. The goal of the agent is to maximize these rewards by applying optimal policies, which is termed as reward maximization.
Answer:
In machine learning, there are mainly two types of models, Parametric and Non-parametric. Here parameters are the predictor variables that are used to build the machine learning model. The explanation of these models are as follow:
Parametric Model: The parametric models use a fixed number of the parameters to create the ML model. It considers strong assumptions about the data. The examples of the parametric models are Linear regression, Logistic Regression, Naïve Bayes, Perceptron, etc.
Non-Parametric Model: The non-parametric model uses flexible numbers of parameters. It considers a few assumptions about the data. These models are good for higher data and no prior knowledge. The examples of the non-parametric models are Decision Tree, K-Nearest Neighbour, SVM with Gaussian kernels, etc.
Answer:
Dropout Technique: The dropout technique is one of the popular techniques to avoid overfitting in the neural network models. It is the regularization technique, in which the randomly selected neurons are dropped during training.
Answer:
Perl Programming language is not commonly used language for AI, as it is the scripting language.
Answer:
Tensor flow is the open-source library platform developed by the Google Brain team. It is a math library used for several machine learning applications. With the help of tensor flow, we can easily train and deploy the machine learning models in the cloud.
Answer:
The market-basket analysis is a popular technique to find the associations between the items. It is frequently used by big retailers in order to get maximum profit. In this approach, we need to find combinations of items that are frequently bought together.
For example, if a person buys coldrink, there are most of the chances that he will buy chips also. Hence, understanding such correlations can help retailers to grow their business by providing relevant offers to their customers.
Answer:
The uniform cost search performs sorting in increasing the cost of the path to a node. It expands the least cost node. It is identical to BFS if each iteration has the same cost. It investigates ways in the expanding order of cost.
Answer:
Alpha–Beta pruning is a search algorithm that tries to reduce the number of nodes that are searched by the minimax algorithm in the search tree. It can be applied to ‘n’ depths and can prune the entire subtrees and leaves.
Answer:
Regularization comes into the picture when a model is either overfit or underfit. It is basically used to minimize the error in a dataset. A new piece of information is fit into the dataset to avoid fitting issues.
Answer:
As we add more and more hidden layers, backpropagation becomes less useful in passing information to the lower layers. In effect, as information is passed back, the gradients begin to vanish and become small relative to the weights of the network.